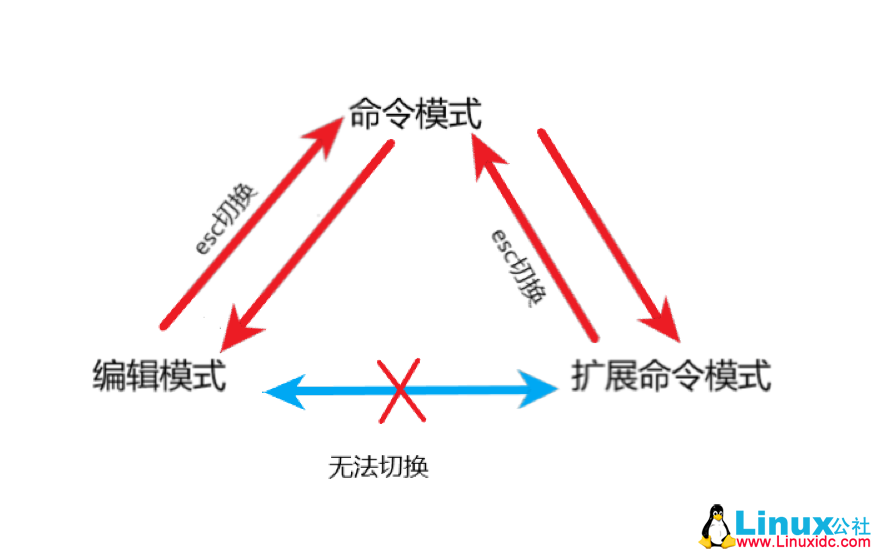
乱码产生的原因:
计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如’a’用什么表示,称为”编码”;反之,将存储在计算机中的二进制数解析显示出来,称为”解码”,如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致’a’解析成’b’或者乱码。
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
UTF-8:
-
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
UTF-8使用一至四个字节为每个字符编码:
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码。
-
其他极少使用的Unicode辅助平面的字符使用四字节编码。
在处理经常会用到的ASCII字符方面非常有效。在处理扩展的拉丁字符集方面也不比UTF-16差。对于中文字符来说,比UTF-32要好。同时,(在这一条上你得相信我,因为我不打算给你展示它的数学原理。)由位操作的天性使然,使用UTF-8不再存在字节顺序的问题了。一份以utf-8编码的文档在不同的计算机之间是一样的比特流。
总体来说,在Unicode字符串中不可能由码点数量决定显示它所需要的长度,或者显示字符串之后在文本缓冲区中光标应该放置的位置;组合字符、变宽字体、不可打印字符和从右至左的文字都是其归因。所以尽管在UTF-8字符串中字符数量与码点数量的关系比UTF-32更为复杂,在实际中很少会遇到有不同的情形。
优点
- UTF-8是ASCII的一个超集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。
- 使用标准的面向字节的排序例程对UTF-8排序将产生与基于Unicode代码点排序相同的结果。(尽管这只有有限的有用性,因为在任何特定语言或文化下都不太可能有仍可接受的文字排列顺序。)
- UTF-8和UTF-16都是可扩展标记语言文档的标准编码。所有其它编码都必须通过显式或文本声明来指定。
- 任何面向字节的字符串搜索算法都可以用于UTF-8的数据(只要输入仅由完整的UTF-8字符组成)。但是,对于包含字符记数的正则表达式或其它结构必须小心。
-
UTF-8字符串可以由一个简单的算法可靠地识别出来。就是,一个字符串在任何其它编码中表现为合法的UTF-8的可能性很低,并随字符串长度增长而减小。举例说,字符值C0,C1,F5至FF从来没有出现。为了更好的可靠性,可以使用正则表达式来统计非法过长和替代值(可以查看W3 FAQ: Multilingual Forms上的验证UTF-8字符串的正则表达式)。
因为每个字符使用不同数量的字节编码,所以寻找串中第N个字符是一个O(N)复杂度的操作 — 即,串越长,则需要更多的时间来定位特定的字符。同时,还需要位变换来把字符编码成字节,把字节解码成字符。
配置字符集:
CentOS6.x 字符集配置文件在/etc/syscconfig/i18n;
CentOS7.x 字符集配置文件在/etc/locale.conf;
查看已经安装的语言包:
|
# locale -a aa_DJ … … |
安装中文字符集:
CentOS6.x:
| #yum groupinstall chinese-support |
注意CentO S7与6不一样;
|
#yum install kde-l10n-Chinese #yum reinstall glibc-common |
查看当前的字符集:
方法一:
| # echo $LANG zh_CN.UTF-8 |
方法二:
| # locale LANG=zh_CN.UTF-8 LC_CTYPE=”zh_CN.UTF-8″ LC_NUMERIC=”zh_CN.UTF-8″ LC_TIME=”zh_CN.UTF-8″ LC_COLLATE=”zh_CN.UTF-8″# locale LANG=zh_CN.UTF-8 LC_CTYPE=”zh_CN.UTF-8″ LC_NUMERIC=”zh_CN.UTF-8″ LC_TIME=”zh_CN.UTF-8″ LC_COLLATE=”zh_CN.UTF-8″ LC_MONETARY=”zh_CN.UTF-8″ LC_MESSAGES=”zh_CN.UTF-8″ LC_PAPER=”zh_CN.UTF-8″ LC_NAME=”zh_CN.UTF-8″ LC_ADDRESS=”zh_CN.UTF-8″ LC_TELEPHONE=”zh_CN.UTF-8″ LC_MEASUREMENT=”zh_CN.UTF-8″ LC_IDENTIFICATION=”zh_CN.UTF-8″ LC_ALL= LC_MONETARY=”zh_CN.UTF-8″ LC_MESSAGES=”zh_CN.UTF-8″ LC_PAPER=”zh_CN.UTF-8″ LC_NAME=”zh_CN.UTF-8″ LC_ADDRESS=”zh_CN.UTF-8″ LC_TELEPHONE=”zh_CN.UTF-8″ LC_MEASUREMENT=”zh_CN.UTF-8″ENTIFICATION=”zh_CN.UTF-8″ LC_A |
安装完成之后通过vi命令修改配置文件:
这个是由中文字符集改为英文字符集,没办法中文字符集还是存在乱码问题;
| #vi /etc/locale.conf # LANG=”zh_CN.UTF-8″ LANG=”en_US.UTF-8″ |
改完后需要使用source命令是配置文件生效:
| #source /etc/locale.conf |
检查:
|
# locale |
临时改变字符集命令:
|
#LANG=”想要使用的字符集” #LANG=”LANG=en_US.UTF-8″ |
| # vim /etc/profile |
注意这个需要利用#source /etc/profile使文件生效。
根据用户设置字符集,需要更改用户家目录下的 .bash_profile ,在最后一行添加字符集就可以了
|
# vim .bash_profile LANG=”LANG=en_US.UTF-8″ |