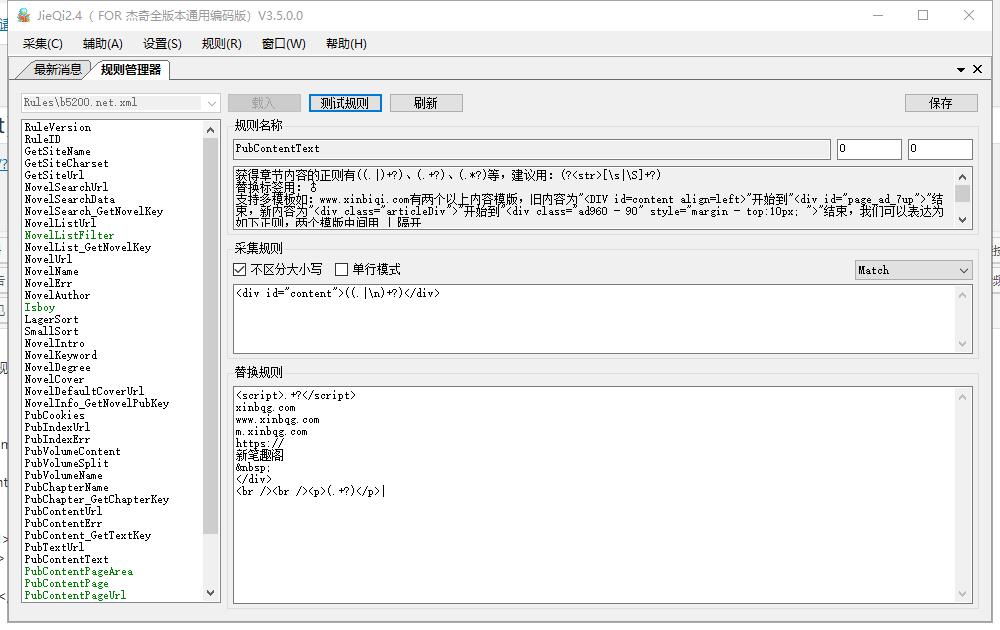
每次有空我都写几个规则,这个规则是利用关关3.5版本 写的是笔趣阁模板的站点,这个站点只需要修改简单的部分代码就可以采集
介绍一下关关采集规则当中需要用到的一些标签
\d* 表示数字 \s* 表示空格+换行 .+? 表示字符(不能为空) .* 表示字符(可以为空)
() 表示我们需要的部分 ((.|\n)*) 章节的内容部分,包括了换行。
=====与杰奇后台标签的对应关系=====
!!!! 相当于 ([^><]*) ~~~~ 相当于 ([^><‘”]*) ^^^^ 相当于 ([^><\d]*) $$$$ 相当于 ([\d]*) **** 相当于 (.*) 如果不行。就根据相关提示调整 复制代码保存为 xml 文件。放在关关规则文件夹里。在关关里面选择即可,规则适用于 V3.5版本
Match None 1 RuleVersion Match None 101 RuleID Match None b5200.net GetSiteName Match IgnoreCase gbk GetSiteCharset Match IgnoreCase Singleline http://www.b5200.net/ GetSiteUrl Match None NovelSearchUrl Match None NovelSearchData Match None NovelSearch_GetNovelKey Match IgnoreCase http://www.b5200.net/ NovelListUrl Match None NovelListFilter Match IgnoreCase <span class="s2"><a href="http://www.b5200.net/\d*_(\d*)/" rel="external nofollow" target="_blank">(.+?)</a> NovelList_GetNovelKey Match IgnoreCase http://www.b5200.net/{NovelKey/1000}_{NovelKey}/ NovelUrl Match IgnoreCase <meta property="og:novel:book_name" content="(.+?)"/> NovelName Match IgnoreCase Singleline 对不起,该文章不存在 NovelErr Match IgnoreCase <meta property="og:novel:author" content="(.+?)"/> NovelAuthor Match None Isboy Match IgnoreCase <meta property="og:novel:category" content="(.+?)"/> LagerSort Match IgnoreCase <meta property="og:novel:category" content="(.+?)"/> SmallSort </div> <div> </p> <p> 作者:.+?<br> 最新章节 :.+?<br> 最新章节预览: Match IgnoreCase <meta property="og:description" content="((.|\n)+?)"/> NovelIntro Match None NovelKeyword b♂连载中 a♂完本 Match IgnoreCase <span class="(.+?)"></span> NovelDegree Match IgnoreCase <meta property="og:image" content="(.+?)"/> NovelCover Match None NovelDefaultCoverUrl Match None <meta property="og:novel:read_url" content="(.+?)"/> NovelInfo_GetNovelPubKey Match None PubCookies Match IgnoreCase http://www.b5200.net/{NovelKey/1000}_{NovelKey}/ PubIndexUrl Match IgnoreCase 无法找到该页 PubIndexErr Match None PubVolumeContent Spilt IgnoreCase <div class="box_con"> PubVolumeSplit Match IgnoreCase <div id="list"> PubVolumeName xinbqg.com www.xinbqg.com m.xinbqg.com http:// https:// 新笔趣阁 </div> Match IgnoreCase <dd><a href="http://www.b5200.net/\d+_\d+/\d+.html" rel="external nofollow" >(.+?)</a></dd> PubChapterName Match IgnoreCase <dd><a href="(http://www.b5200.net/\d+_\d+/\d+.html)" rel="external nofollow" >.+?</a></dd> PubChapter_GetChapterKey Match IgnoreCase {ChapterKey} PubContentUrl Match None 您访问的页面可能暂时未更新、已更名或已经删除,请稍后访问或马上点此举报: PubContentErr Match None PubContent_GetTextKey Match None PubTextUrl <script>.+?</script> xinbqg.com www.xinbqg.com m.xinbqg.com https:// 新笔趣阁 </div> <br /><br /><p>(.+?)</p>| Match IgnoreCase <div id="content">((.|\n)+?)</div> PubContentText Match None PubContentPageArea Match None PubContentPage Match None PubContentPageUrl Match None PubContentPageKey Match None PubContentChapterName Match None PubContentChapterNum Match None PubContentImages Match None PubContentReplace