kafka是一种消息队列,该消息队列实现了数据的持久化直到消息被处理完,采用了基于数据的接口层,实现了两个相互通信功能模块的解耦,具有扩展性、灵活性和可处理性。kafka可以实现消息的广播,使不同的消费组消费同样的数据,同时保证了数据在消息队列中的顺序。kafka在写入数据时有缓冲并且使用了异步通信,用户想什么时候消费数据都可以。KafkaOffsetMonitor是用来监测kafka集群中消费者组对topic的消费情况,以及它们在partition中的offset(偏移量)。
工具/原料
- CentOS 7
方法/步骤
- 1
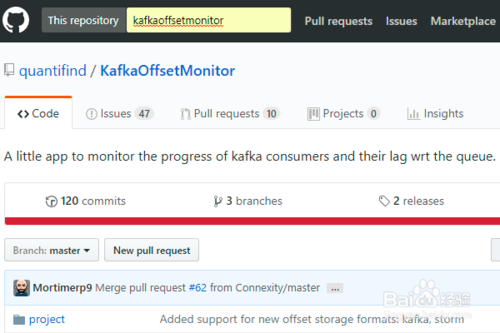
在github上搜索KafkaOffsetMonitor,如下图所示,在This repository后面的框中输入KafkaOffsetMonitor然后点击回车,便可以在github中找到该项目。我们可以看到该项目有3个分支,2个发布的版本,但是最近一次更新的时间是2015年8月,我们暂且先尝试一下该工具是否可以有效的监测kafka。其实还有其他的监控工具,例如Kafka Web Console和雅虎开源的Kafka集群管理器(Kafka Manager),有机会的话再介绍其他的工具。
- 2
我们在搜索到的页面下拉,在Running It处点击current.jar下载KafkaOffsetMonitor-assembly-0.2.1.jar文件,下图中官方给出了启动这个jar文件的命令。我们在跳转后的Downloads页面下载该文件。


- 3
一般我们使用网页下载都非常的慢,因此在链接上点击右键,选择复制下载链接,然后打开迅雷将链接复制过去进行下载,如下图所示。

- 4
我们使用第三方软件(Secure CRT)将下载后的jar文件上传到CentOS7的路径下面,在kafka的解压缩目录下的bin目录中使用mkdir命令创建一个monitor文件夹,将KafkaOffsetMonitor-assembly-0.2.1.jar文件放到该文件夹中,如下图所示。

- 5
我们在该文件夹中使用vi命令创建一个kafka-monitor的文件,在该文件中输入以下的java命令,用于启动KafkaOffsetMonitor-assembly-0.2.1.jar文件,如下图所示,编辑完成后保存退出。

- 6
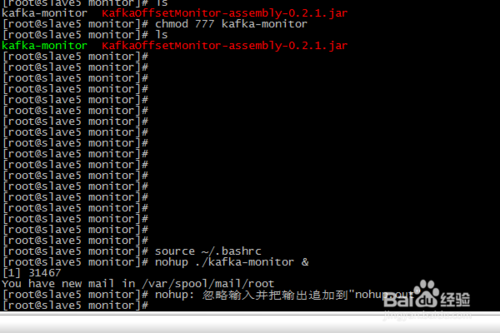
文件编辑完成后,我们在monitor目录下查看该文件,发现该文件并不是一个可执行的文件,这是因为我们没有给kafka-monitor文件可执行的权限,使用chmod命令赋值该文件执行的权限,修改后的结果如下图所示。

- 7
接着我们使用nohup ./kafka-monitor &后台执行该文件,如下图所示。我们在可执行文件中设置的port为18089,因此我们在浏览器中访问这台机器的18089端口即可查看kafka的数据消费情况,该端口号可以设置为其他。
 END
END
注意事项
- 注意启动jar文件的命令中参数的设置。